
Python Eğitimi ile Veri Bilimini Sıfırdan Öğrenin
Python Eğitimi ile Veri Bilimini Sıfırdan Öğrenin
Python Eğitimi ile Veri Bilimini Sıfırdan Öğrenin
Python Eğitimi ile Veri Bilimini Sıfırdan Öğrenin! Birkaç yıl önce oldu. SAS üzerinde 5 yıldan fazla çalıştıktan sonra konfor alanımdan çıkmaya karar verdim. Bir veri bilimcisi olarak, diğer faydalı araçları arayışım DEVAM ETMEKTEDİR! Neyse ki karar vermem uzun sürmedi – Python benim mezemdi.
Her zaman kodlamaya yatkınlığım vardı. Bu gerçekten sevdiğim şeyi yapma zamanıydı. Kod. Anlaşıldı, kodlama aslında oldukça kolaydı!
Python’un temellerini bir hafta içinde öğrendim . Ve o zamandan beri, sadece bu dili derinlemesine araştırmakla kalmadım, aynı zamanda diğer birçok kişinin bu dili öğrenmesine yardımcı oldum. Python başlangıçta genel amaçlı bir dildi. Ancak yıllar içinde, güçlü topluluk desteğiyle bu dil, veri analizi ve tahmine dayalı modelleme için özel bir kitaplık aldı.
Veri bilimi için python konusunda kaynak eksikliğinden dolayı, diğer birçok kişinin python’u daha hızlı öğrenmesine yardımcı olmak için bu öğreticiyi oluşturmaya karar verdim. Bu eğitimde, Veri Analizi için Python’u nasıl kullanacağımız hakkında bilgi alacağız, rahat olana kadar çiğneyeceğiz ve kendi tarafımızda uygulayacağız.
Veri biliminde sıfırdan eksiksiz bir python eğitimi.
Veri bilimi ve makine öğreniminde yolculuğunuza başlamak için bir yer arayan yeni başlayan biri misiniz? Sadece sizin için hazırlanmış, bilgi ve veri bilimi öğrenimiyle dolu kapsamlı bir kurs sunuyoruz!
Ayrıca , veri bilimi dünyasına kapsamlı bir giriş olan ‘ Veri Bilimine Giriş ‘ kurslarına da arama motorlarından göz atabilirsiniz. Ellerinizi kirletmek için Python, İstatistik ve Öngörülü Modelleme modüllerinin yanı sıra çok sayıda pratik proje içerir.
Veri Analizi için Python’un Temelleri
Veri analizi için neden Python öğrenmelisiniz?
Python, veri analizi için bir dil seçimi olarak son zamanlarda çok ilgi topladı. Bir süre önce Python’un temelleri vardı . Python öğrenmenin lehine olan bazı nedenler:
- Açık Kaynak – kurulumu ücretsiz
- Harika çevrimiçi topluluk
- öğrenmesi çok kolay
- Veri bilimi ve web tabanlı analitik ürünlerinin üretimi için ortak bir dil haline gelebilir.
Söylemeye gerek yok, yine de birkaç dezavantajı var:
- Derlenmiş dilden ziyade yorumlanmış bir dildir – bu nedenle daha fazla CPU zamanı alabilir. Bununla birlikte, programcı zamanındaki tasarruf göz önüne alındığında (öğrenme kolaylığı nedeniyle), yine de iyi bir seçim olabilir.
Python 2.7 v/s 3.4
Bu Python’da en çok tartışılan konulardan biridir. Özellikle yeni başlayan biriyseniz, onunla her zaman yollarınız kesişecektir. Burada doğru/yanlış bir seçim yoktur. Tamamen duruma ve kullanım ihtiyacınıza bağlıdır. Bilgilendirilmiş bir seçim yapmanıza yardımcı olacak bazı ipuçları vermeye çalışacağım.
Neden Python 2.7?
- Müthiş topluluk desteği! Bu, ilk günlerinizde ihtiyaç duyacağınız bir şey. Python 2, 2000 yılının sonlarında piyasaya sürüldü ve 15 yıldan fazla bir süredir kullanılmaktadır.
- Çok sayıda üçüncü taraf kitaplığı! Pek çok kitaplık 3.x desteği sağlasa da, yine de çok sayıda modül yalnızca 2.x sürümlerinde çalışır. Python’u web geliştirme gibi harici modüllere yüksek oranda güvenerek belirli uygulamalar için kullanmayı planlıyorsanız, 2.7 ile daha iyi durumda olabilirsiniz.
- 3.x sürümlerinin bazı özellikleri geriye dönük uyumluluğa sahiptir ve 2.7 sürümü ile çalışabilir.
Neden Python 3.4?
- Daha temiz ve daha hızlı! Python geliştiricileri, gelecek için daha güçlü bir temel oluşturmak için bazı yapısal aksaklıkları ve küçük dezavantajları düzeltti. Bunlar başlangıçta çok alakalı olmayabilir, ancak sonunda önemli olacaktır.
- Bu gelecek! 2.7, 2.x ailesinin son sürümüdür ve sonunda herkesin 3.x sürümlerine geçmesi gerekir. Python 3, son 5 yıldır kararlı sürümler yayınladı ve aynı şekilde devam edecek.
Net bir kazanan yok ama sanırım sonuç olarak Python’u bir dil olarak öğrenmeye odaklanmalısınız. Sürümler arasında geçiş yapmak sadece bir zaman meselesi olmalıdır. Yakın gelecekte Python 2.x vs 3.x hakkında özel bir makale için bizi izlemeye devam edin!
Python nasıl kurulur?
Python’u kurmak için 2 yaklaşım vardır:
- Python’u doğrudan proje sitesinden indirebilir ve istediğiniz bağımsız bileşenleri ve kitaplıkları kurabilirsiniz .
- Alternatif olarak, önceden yüklenmiş kitaplıklarla birlikte gelen bir paketi indirebilir ve kurabilirsiniz. Anaconda’yı indirmenizi tavsiye ederim . Başka bir seçenek de Enthinky Canopy Express olabilir .
İkinci yöntem sorunsuz bir kurulum sağlar ve bu nedenle yeni başlayanlara bunu tavsiye edeceğim. Bu yaklaşımın taklidi, tek bir kitaplığın en son sürümüyle ilgileniyor olsanız bile, tüm paketin yükseltilmesini beklemeniz gerektiğidir. En son istatistiksel araştırmalar yapana kadar ve olmadıkça, ve olmadıkça önemli olmamalıdır.
Bir geliştirme ortamı seçme
Python’u kurduktan sonra, bir ortam seçmek için çeşitli seçenekler vardır. İşte en yaygın 3 seçenek:
Python için IDLE editörü
Doğru ortam sizin ihtiyacınıza bağlı olsa da, ben şahsen iPython Notebook’ları çok tercih ediyorum. Kodun kendisini yazarken belgelemek için birçok iyi özellik sağlar ve kodu bloklar halinde çalıştırmayı seçebilirsiniz (satır satır yürütme yerine)
Bu eksiksiz eğitim için iPython ortamını kullanacağız.
Isınma: İlk Python programınızı çalıştırma
Başlangıç için Python’u basit bir hesap makinesi olarak kullanabilirsiniz:
Dikkat edilmesi gereken birkaç şey
- Çalıştığınız işletim sistemine bağlı olarak terminal / cmd’nize “ipython notebook” yazarak iPython notebook’u başlatabilirsiniz.
- Bir iPython not defterini, yukarıdaki ekran görüntüsündeki – UntitledO ismine tıklayarak adlandırabilirsiniz.
- Arayüz, girişler için In [*] ve çıkış için Out[*] gösterir.
- Ardından bir satır daha eklemek isterseniz “Shift + Enter” veya “ALT + Enter” tuşlarına basarak bir kodu çalıştırabilirsiniz.
Problem çözmeye derinlemesine dalmadan önce, bir adım geriye gidelim ve Python’un temellerini anlayalım. Bildiğimiz gibi, veri yapıları, yineleme ve koşullu yapılar herhangi bir dilin temelini oluşturur. Python’da bunlar listeleri, dizileri, tuple’ları, sözlükleri, for-loop, while-loop, if-else, vb. içerir. Bunlardan bazılarına bir göz atalım.
Python kütüphaneleri ve Veri Yapıları
Python Veri Yapıları
Aşağıda Python’da kullanılan bazı veri yapıları verilmiştir. Bunları uygun şekilde kullanmak için onlara aşina olmalısınız.
- Listeler – Listeler, Python’daki en çok yönlü veri yapılarından biridir. Bir liste, köşeli parantez içinde virgülle ayrılmış değerlerin bir listesi yazılarak basitçe tanımlanabilir. Listeler farklı türde öğeler içerebilir, ancak genellikle öğelerin tümü aynı türdedir. Python listeleri değişkendir ve bir listenin tek tek öğeleri değiştirilebilir.
Bir listeyi tanımlayıp ona erişmek için hızlı bir örnek:

- Dizeler – Dizeler, tek ( ‘ ), çift ( ” ) veya üçlü ( ”’ ) ters virgül kullanılarak tanımlanabilir. İşkembe tırnak içine alınmış ( ”’ ) dizeler birden çok satıra yayılabilir ve belge dizilerinde (Python’un işlevleri belgeleme yöntemi) sıklıkla kullanılır. \ kaçış karakteri olarak kullanılır. Lütfen Python dizelerinin değişmez olduğunu unutmayın, bu nedenle dizelerin bir kısmını değiştiremezsiniz.
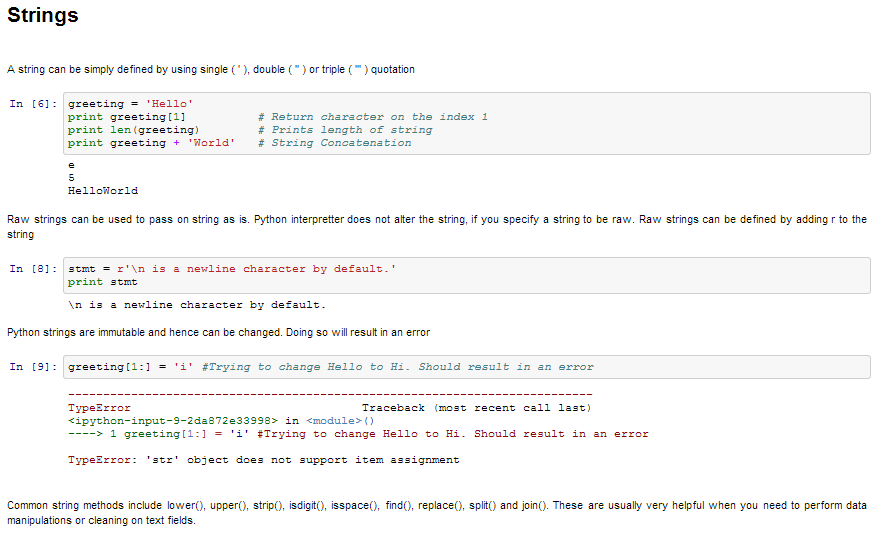
- Tuples – Bir demet, virgülle ayrılmış bir dizi değerle temsil edilir. Tuple’lar değişmezdir ve çıktı, iç içe geçmiş tuple’ların doğru şekilde işlenmesi için parantez içine alınır. Ek olarak, demetler değişmez olsa da, gerektiğinde değişken verileri tutabilirler.
Tuple’lar değişmez olduklarından ve değiştirilemedikleri için listelere göre daha hızlı işlenirler. Bu nedenle, listenizin değişmesi olası değilse, listeler yerine tuples kullanmalısınız.
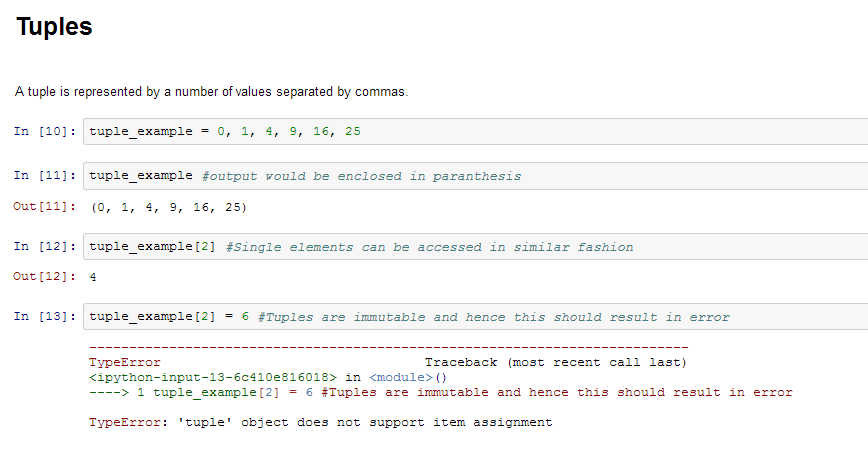
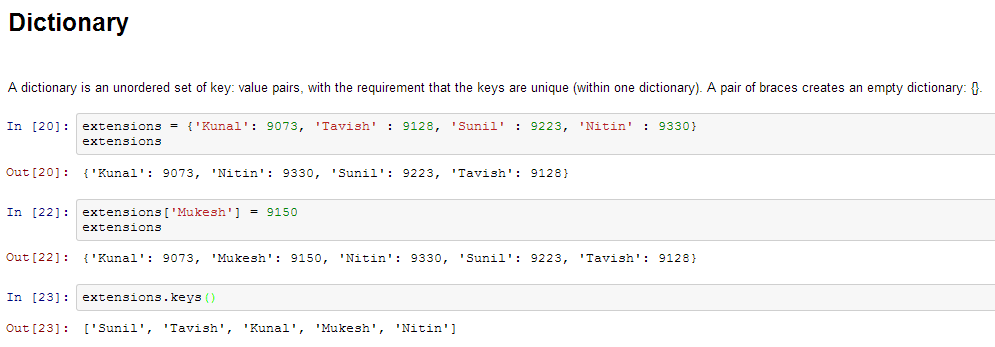
- Sözlük – Sözlük , sırasız bir anahtar kümesidir : anahtarların benzersiz olması şartıyla (bir sözlük içinde) değer çiftleri. Bir çift parantez boş bir sözlük oluşturur: {} .
Python Yineleme ve Koşullu Yapılar
Çoğu dilde olduğu gibi Python’da da yineleme için en yaygın kullanılan yöntem olan bir FOR döngüsü vardır. Basit bir sözdizimine sahiptir:
[Python Yinelenebilir] içindeki i için: ifade(i)
Burada “Python Iterable” bir liste, demet veya sonraki bölümlerde inceleyeceğimiz diğer gelişmiş veri yapıları olabilir. Bir sayının faktöriyelini belirleyen basit bir örneğe bakalım.
gerçek=1 i aralığında (1,N+1): gerçek *= ben
Koşullu ifadelere gelince, bunlar bir koşula dayalı olarak kod parçalarını yürütmek için kullanılır. En sık kullanılan yapı, aşağıdaki sözdizimiyle if-else’dir:
eğer [koşul]: __eğer doğruysa yürütme__ Başka: __yanlışsa yürütme__
Örneğin, N sayısının çift mi yoksa tek mi olduğunu yazdırmak istersek:
N%2 == 0 ise:
yazdır ('Eşit')
Başka:
yazdır ('Tek')
Artık Python temellerine aşina olduğunuza göre, bir adım daha ileri gidelim. Aşağıdaki görevleri gerçekleştirmeniz gerekiyorsa ne olur:
- 2 matrisi çarp
- İkinci dereceden bir denklemin kökünü bulun
- Çubuk grafikleri ve histogramları çizin
- İstatistiksel modeller yapın
- Web sayfalarına erişin
Sıfırdan kod yazmaya çalışırsanız, bu bir kabus olacak ve Python’da 2 günden fazla kalmayacaksınız! Ama bunun için endişelenmeyelim. Neyse ki, doğrudan kodumuza aktarabileceğimiz ve hayatımızı kolaylaştırabileceğimiz önceden tanımlanmış birçok kitaplık var.
Örneğin, az önce gördüğümüz faktöriyel örneği ele alalım. Bunu tek adımda şu şekilde yapabiliriz:
matematik.faktöriyel(N)
Elbette bunun için matematik kütüphanesini içe aktarmamız gerekiyor. Sıradaki çeşitli kütüphaneleri keşfedelim.
Python Kitaplıkları
Faydalı kütüphaneler ile tanışarak Python öğrenme yolculuğumuzda bir adım öne geçelim. İlk adım, onları çevremize aktarmayı öğrenmektir. Python’da bunu yapmanın birkaç yolu vardır:
matematiği m olarak içe aktar
matematik içe aktarmadan *
İlk olarak, kütüphane matematiğine bir takma ad m tanımladık. Artık matematik kitaplığındaki çeşitli işlevleri (örn. faktöriyel) m.factorial() takma adını kullanarak referans vererek kullanabiliriz.
İkinci şekilde, matematikteki tüm ad alanını içe aktardınız, yani matematiğe başvurmadan doğrudan factorial() öğesini kullanabilirsiniz.İpucu: Google, işlevlerin nereden geldiğini bileceğiniz için, kitaplıkları içe aktarmanın ilk stilini kullanmanızı önerir.
Aşağıda, herhangi bir bilimsel hesaplama ve veri analizi için ihtiyaç duyacağınız kitaplıkların bir listesi bulunmaktadır:
- NumPy , Sayısal Python anlamına gelir. NumPy’nin en güçlü özelliği n boyutlu dizidir. Bu kütüphane aynı zamanda temel lineer cebir fonksiyonları, Fourier dönüşümleri, gelişmiş rasgele sayı yetenekleri ve Fortran, C ve C++ gibi diğer düşük seviyeli dillerle entegrasyon için araçlar içerir.
- SciPy Bilimsel Python anlamına gelir. SciPy, NumPy üzerine kurulmuştur. Ayrık Fourier dönüşümü, Lineer Cebir, Optimizasyon ve Seyrek matrisler gibi çeşitli üst düzey bilim ve mühendislik modülleri için en kullanışlı kütüphanelerden biridir.
- Matplotlib , histogramlardan çizgi grafiklerine ve ısı grafiklerine kadar çok çeşitli grafikleri çizmek için. Bu çizim özelliklerini inline kullanmak için ipython notebook’ta (ipython notebook –pylab = inline) Pylab özelliğini kullanabilirsiniz. Satır içi seçeneği yok sayarsanız, pylab ipython ortamını Matlab’a çok benzeyen bir ortama dönüştürür. Arsanıza matematik eklemek için Lateks komutlarını da kullanabilirsiniz.
- Yapılandırılmış veri işlemleri ve manipülasyonları için pandalar . Veri toplama ve hazırlama için yaygın olarak kullanılır. Pandalar Python’a nispeten yakın zamanda eklendi ve Python’un veri bilimcisi topluluğunda kullanımını artırmada etkili oldu.
- Makine öğrenimi için Scikit Learn . NumPy, SciPy ve matplotlib üzerine inşa edilen bu kitaplık, sınıflandırma, regresyon, kümeleme ve boyut azaltma dahil olmak üzere makine öğrenimi ve istatistiksel modelleme için birçok verimli araç içerir.
- İstatistiksel modelleme için istatistik modelleri. Statsmodels, kullanıcıların verileri keşfetmesine, istatistiksel modelleri tahmin etmesine ve istatistiksel testler gerçekleştirmesine olanak tanıyan bir Python modülüdür. Farklı veri türleri ve her tahmin edici için kapsamlı bir tanımlayıcı istatistik, istatistiksel testler, çizim işlevleri ve sonuç istatistikleri listesi mevcuttur.
- İstatistiksel veri görselleştirme için Seaborn . Seaborn, Python’da çekici ve bilgilendirici istatistiksel grafikler oluşturmaya yönelik bir kütüphanedir. Matplotlib tabanlıdır. Seaborn, görselleştirmeyi verileri keşfetmenin ve anlamanın merkezi bir parçası haline getirmeyi amaçlar.
- Modern web tarayıcılarında etkileşimli grafikler, gösterge tabloları ve veri uygulamaları oluşturmak için Bokeh . Kullanıcının D3.js tarzında zarif ve özlü grafikler oluşturmasını sağlar. Ayrıca, çok büyük veya akış veri kümeleri üzerinde yüksek performanslı etkileşim yeteneğine sahiptir.
- Numpy ve Pandas’ın yeteneklerini dağıtılmış ve akışlı veri kümelerine genişletmek için Blaze . Bcolz, MongoDB, SQLAlchemy, Apache Spark, PyTables vb. dahil olmak üzere çok sayıda kaynaktan gelen verilere erişmek için kullanılabilir. Blaze, Bokeh ile birlikte çok büyük veri yığınları üzerinde etkili görselleştirmeler ve gösterge tabloları oluşturmak için çok güçlü bir araç olarak hareket edebilir.
- Web taraması için scrapy . Belirli veri kalıplarını almak için çok kullanışlı bir çerçevedir. Bir web sitesi ana url’sinden başlama ve daha sonra bilgi toplamak için web sitesindeki web sayfalarını inceleme yeteneğine sahiptir.
- Sembolik hesaplama için SymPy . Temel sembolik aritmetikten kalkülüs, cebir, ayrık matematik ve kuantum fiziğine kadar geniş kapsamlı yeteneklere sahiptir. Bir başka kullanışlı özellik, hesaplamaların sonucunu LaTeX kodu olarak biçimlendirme yeteneğidir.
- Web’e erişim talepleri . Standart python kitaplığı urllib2’ye benzer şekilde çalışır ancak kodlaması çok daha kolaydır. urllib2 ile küçük farklılıklar bulacaksınız, ancak yeni başlayanlar için İstekler daha uygun olabilir.
Ek kitaplıklar, şunlara ihtiyacınız olabilir:
- İşletim sistemi ve dosya işlemleri için işletim sistemi
- grafik tabanlı veri manipülasyonları için networkx ve igraph
- metin verilerindeki kalıpları bulmak için düzenli ifadeler
- Web hurdaya çıkarmak için BeautifulSoup . Bir çalıştırmada yalnızca tek bir web sayfasından bilgi çıkaracağı için Scrapy’den daha düşüktür.
Artık Python temellerine ve ek kitaplıklara aşina olduğumuza göre, Python aracılığıyla problem çözmeye derin bir dalış yapalım. Evet, tahmine dayalı bir model yapmayı kastediyorum! Bu süreçte, bazı güçlü kütüphaneler kullanıyoruz ve ayrıca bir sonraki veri yapılarıyla karşılaşıyoruz. Sizi 3 önemli aşamadan geçireceğiz:
- Veri Keşfi – sahip olduğumuz veriler hakkında daha fazla bilgi edinmek
- Data Munging – verileri temizleme ve istatistiksel modellemeye daha iyi uyması için onunla oynama
- Öngörülü Modelleme – gerçek algoritmaları çalıştırmak ve eğlenmek
3. Pandaları kullanarak Python’da keşif analizi
Verilerimizi daha fazla araştırmak için sizi başka bir hayvanla tanıştırayım (Sanki Python yetmezmiş gibi!) – Pandalar
Resim Kaynağı: Vikipedi
Pandalar, Python’daki en kullanışlı veri analiz kitaplıklarından biridir (bu isimlerin kulağa tuhaf geldiğini biliyorum, ama bekleyin!). Veri bilimi topluluğunda Python kullanımını artırmada etkili oldular. Şimdi bir Analytics Vidhya yarışmasından bir veri seti okumak, keşif analizi yapmak ve bu sorunu çözmek için ilk temel kategorizasyon algoritmamızı oluşturmak için Pandaları kullanacağız.
Verileri yüklemeden önce Pandalardaki 2 temel veri yapısını anlayalım – Seriler ve Veri Çerçeveleri
Serilere ve Veri Çerçevelerine Giriş
Seriler, 1 boyutlu etiketli/indekslenmiş dizi olarak anlaşılabilir. Bu serinin tek tek öğelerine bu etiketler aracılığıyla erişebilirsiniz.
Veri çerçevesi Excel çalışma kitabına benzer – sütunlara atıfta bulunan sütun adlarınız ve satır numaraları kullanılarak erişilebilen satırlarınız var. Temel fark, sütun adları ve satır numaralarının veri çerçeveleri durumunda sütun ve satır dizini olarak bilinmesidir.
Seriler ve veri çerçeveleri, Python’daki Pandalar için temel veri modelini oluşturur. Veri kümeleri önce bu veri çerçevelerini okur ve daha sonra çeşitli işlemler (örneğin gruplama, toplama vb.) sütunlarına çok kolay bir şekilde uygulanabilir.
Devamı: Pandalara 10 Dakika
Alıştırma veri seti – Kredi Tahmin Problemi
Veri setini buradan indirebilirsiniz . İşte değişkenlerin açıklaması:
DEĞİŞKEN AÇIKLAMALAR: Değişken Açıklama Loan_ID Benzersiz Kredi Kimliği Cinsiyet Erkek Kadın Evli Başvuru Sahibi evli (E/H) Bağımlılar Bağımlıların sayısı Eğitim Adayı Eğitimi (Lisans/Lisans) Serbest Meslek Sahibi Serbest Meslek Sahibi (E/H) Başvuru Sahibinin Geliri Başvuru Sahibinin Geliri Başvuru Sahibinin Geliri Eş Başvuru Sahibinin Geliri LoanAmount Kredi tutarı bin olarak Loan_Amount_Term Kredinin ay cinsinden vadesi Credit_History kredi geçmişi yönergelere uygundur Property_Area Kentsel/ Yarı Kentsel/ Kırsal Kredi_Durumu Kredi onaylandı (E/H)
Keşfetmeye başlayalım
Başlamak için, terminal/windows komut isteminize aşağıdakileri yazarak Inline Pylab modunda iPython arayüzünü başlatın:
ipython not defteri --pylab=satır içi
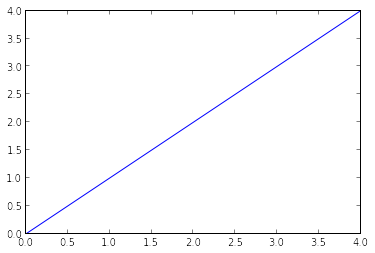
Bu, iPython not defterini, halihazırda içe aktarılmış birkaç yararlı kitaplığa sahip olan pylab ortamında açar. Ayrıca, verilerinizi satır içi olarak çizebileceksiniz, bu da bunu etkileşimli veri analizi için gerçekten iyi bir ortam haline getiriyor. Aşağıdaki komutu yazarak (ve aşağıdaki şekilde görüldüğü gibi çıktıyı alarak) ortamın doğru yüklenip yüklenmediğini kontrol edebilirsiniz:
arsa(aragen(5))
Şu anda Linux’ta çalışıyorum ve veri kümesini aşağıdaki konumda sakladım:
/home/kunal/Downloads/Loan_Prediction/train.csv
Kitaplıkları ve veri kümesini içe aktarma:
Bu eğitim sırasında kullanacağımız kütüphaneler şunlardır:
- dizi
- matplotlib
- pandalar
Pylab ortamı nedeniyle matplotlib ve numpy’yi içe aktarmanız gerekmediğini lütfen unutmayın. Kodu farklı bir ortamda kullanmanız durumunda onları hala kodda tuttum.
Kitaplığı içe aktardıktan sonra, read_csv() işlevini kullanarak veri kümesini okursunuz. Bu aşamaya kadar kod şöyle görünür:
pandaları pd olarak içe aktar
numpy'yi np olarak içe aktar
matplotlib'i plt olarak içe aktar
%matplotlib satır içi
df = pd.read_csv("/home/kunal/Downloads/Loan_Prediction/train.csv") #Pandas kullanarak bir veri çerçevesindeki veri kümesini okuma
Hızlı Veri Keşfi
Veri kümesini okuduktan sonra, head() işlevini kullanarak birkaç üst satıra göz atabilirsiniz.
df.kafa(10)
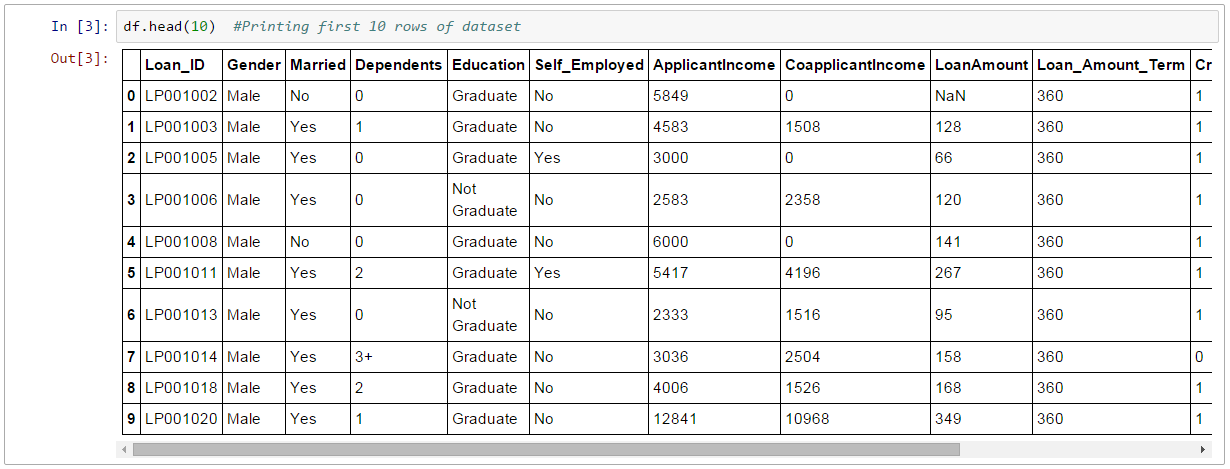
Bu 10 satır yazdırmalıdır. Alternatif olarak, veri kümesini yazdırarak daha fazla satıra da bakabilirsiniz.
Ardından, tarif() işlevini kullanarak sayısal alanların özetine bakabilirsiniz.
df.describe()
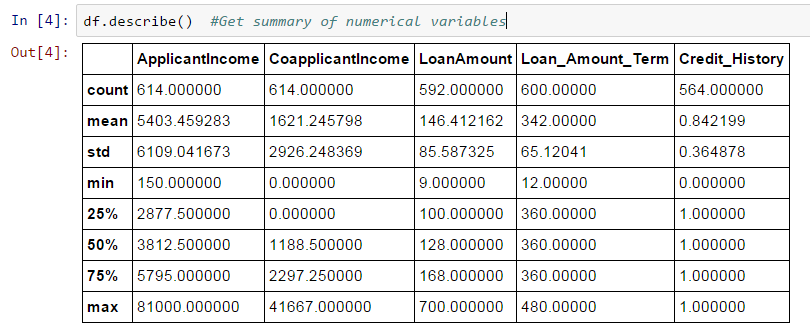
tanımlama () işlevi çıktısında sayı, ortalama, standart sapma (std), min, çeyrekler ve maksimum sağlar ( Nüfus dağılımını anlamak için temel istatistikleri yenilemek için bu makaleyi okuyun)
İşte birkaç çıkarım, tarif() fonksiyonunun çıktısına bakarak çizebilirsiniz:
- LoanAmount (614 – 592) 22 eksik değere sahiptir.
- Loan_Amount_Term (614 – 600) 14 eksik değere sahip.
- Credit_History (614 – 564) 50 eksik değere sahiptir.
- Ayrıca başvuranların yaklaşık %84’ünün bir kredi geçmişine sahip olduğuna da bakabiliriz. Nasıl? Credit_History alanının ortalaması 0.84’tür (Unutmayın, Credit_History, kredi geçmişi olanlar için 1, aksi takdirde 0 değerindedir)
- ApplicantIncome dağılımı beklentiyle uyumlu görünüyor. CoapplicantIncome ile aynı
Ortalamayı medyanla, yani %50 rakamıyla karşılaştırarak verilerde olası bir çarpıklık hakkında bir fikir edinebileceğimizi lütfen unutmayın.
Sayısal olmayan değerler için (örn. Property_Area, Credit_History vb.), mantıklı olup olmadıklarını anlamak için frekans dağılımına bakabiliriz. Sıklık tablosu aşağıdaki komutla yazdırılabilir:
df['Property_Area'].value_counts()
Benzer şekilde, kredi geçmişinin benzersiz değerlerine bakabiliriz. dfname[‘column_name’] öğesinin, veri çerçevesinin belirli bir sütununa erişmek için temel bir dizin oluşturma tekniği olduğuna dikkat edin. Sütunların bir listesi de olabilir. Daha fazla bilgi için yukarıda paylaşılan “Pandalara 10 Dakika” kaynağına bakın.
dağıtım analizi
Artık temel veri özelliklerine aşina olduğumuza göre, çeşitli değişkenlerin dağılımını inceleyelim. Sayısal değişkenlerle başlayalım – yani ApplicantIncome ve LoanAmount
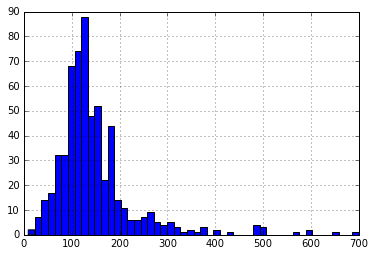
Aşağıdaki komutları kullanarak ApplicantIncome histogramını çizerek başlayalım:
df['ApplicantIncome'].hist(bins=50)
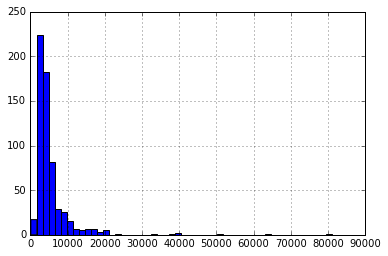
Burada çok az uç değer olduğunu gözlemliyoruz. Dağıtımı net bir şekilde göstermek için 50 kutunun gerekli olmasının nedeni de budur.
Daha sonra, dağılımları anlamak için kutu çizimlerine bakacağız. Ücret için kutu grafiği şu şekilde çizilebilir:
df.boxplot(sütun='BaşvuranGelir')
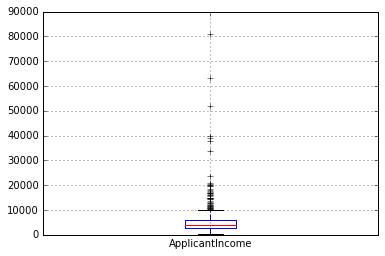
Bu, birçok aykırı/aşırı değerin varlığını doğrular. Bu, toplumdaki gelir eşitsizliğine bağlanabilir. Bunun bir kısmı, farklı eğitim seviyelerine sahip insanlara bakıyor olmamızdan kaynaklanabilir. Bunları Eğitime göre ayıralım:
df.boxplot(column='ApplicantIncome', by = 'Eğitim')
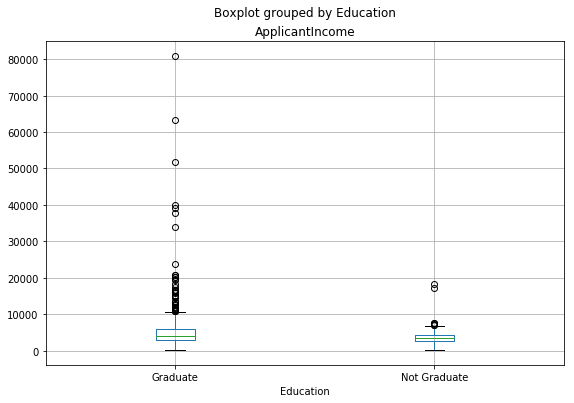
Mezun ve mezun olmayanların ortalama gelirleri arasında önemli bir fark olmadığını görebiliriz. Ancak, çok yüksek gelirli mezunların sayısı, aykırı gibi görünen daha fazla sayıdadır.
Şimdi, aşağıdaki komutu kullanarak LoanAmount’un histogramına ve kutu grafiğine bakalım:
df['KrediTutarı'].hist(binler=50)
df.boxplot(sütun='Kredi Tutarı')
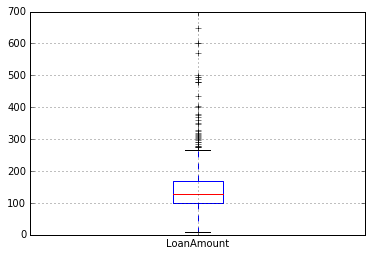
Yine, bazı uç değerler var. Açıkça, hem ApplicantIncome hem de LoanAmount, bir miktar veri mugging gerektirir. LoanAmount eksik ve uç değerlere sahipken, ApplicantIncome daha derin bir anlayış gerektiren birkaç uç değere sahiptir. Bunu ilerleyen bölümlerde ele alacağız.
Kategorik değişken analizi
Artık ApplicantIncome ve LoanIncome dağılımlarını anladığımıza göre, kategorik değişkenleri daha ayrıntılı olarak anlayalım. Excel stili pivot tablo ve çapraz tablo kullanacağız. Örneğin, kredi geçmişine dayalı bir kredi alma şansına bakalım. Bu, MS Excel’de bir pivot tablo kullanılarak şu şekilde gerçekleştirilebilir:
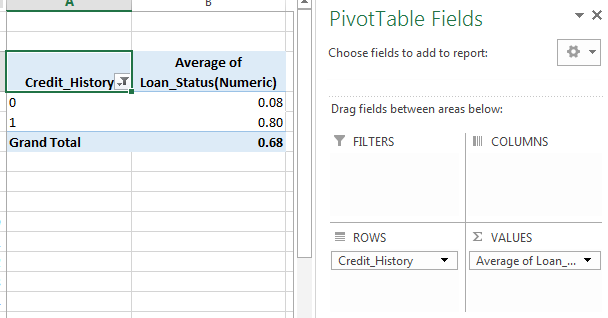
Not: Burada kredi durumu Evet için 1 ve Hayır için 0 olarak kodlanmıştır. Dolayısıyla ortalama kredi alma olasılığını temsil etmektedir.
Şimdi Python kullanarak benzer bir içgörü oluşturmak için gereken adımlara bakacağız. Pandalardaki farklı veri işleme tekniklerini öğrenmek için lütfen bu makaleye bakın.
temp1 = df['Credit_History'].value_counts(artan=Doğru)
temp2 = df.pivot_table(values='Loan_Status',index=['Credit_History'],aggfunc=lambda x: x.map({'Y':1,'N':0}).mean())
print ('Kredi Geçmişi için Sıklık Tablosu:')
yazdır (temp1)
print ('\nHer Kredi Geçmişi sınıfı için kredi alma olasılığı:')
yazdır (temp2)

Şimdi MS Excel’dekine benzer bir pivot_table aldığımızı gözlemleyebiliriz. Bu, aşağıdaki kodla “matplotlib” kitaplığı kullanılarak bir çubuk grafik olarak çizilebilir:
matplotlib.pyplot'u plt olarak içe aktar
incir = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Kredi_History')
ax1.set_ylabel('Başvuru Sahibi Sayısı')
ax1.set_title("Credit_History'ye Göre Başvuru Sahipleri")
temp1.plot(tür='bar')
ax2 = fig.add_subplot(122)
temp2.plot(tür = 'çubuk')
ax2.set_xlabel('Kredi_History')
ax2.set_ylabel('Kredi alma olasılığı')
ax2.set_title("Kredi geçmişine göre kredi alma olasılığı")
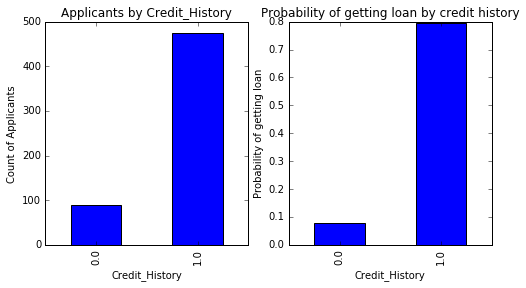
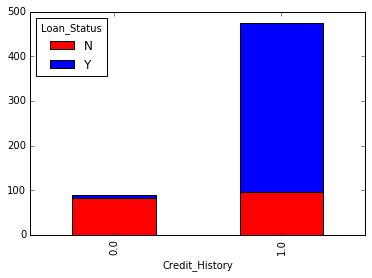
Bu, başvuru sahibinin geçerli bir kredi geçmişine sahip olması durumunda kredi alma şansının sekiz kat olduğunu göstermektedir. Evli, Serbest Meslek Sahibi, Property_Area, vb. ile benzer grafikler çizebilirsiniz.
Alternatif olarak, bu iki grafik, yığılmış bir grafikte birleştirilerek de görselleştirilebilir:
temp3 = pd.crosstab(df['Kredi_History'], df['Kredi_Durumu']) temp3.plot(tür='bar', yığınlanmış=Doğru, renk=['kırmızı','mavi'], ızgara=Yanlış)
Karışıma cinsiyet de ekleyebilirsiniz (Excel’deki pivot tabloya benzer):
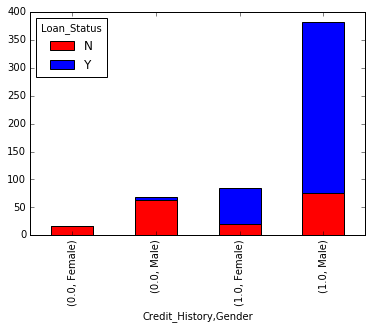
Henüz fark etmediyseniz, burada biri kredi geçmişine, diğeri ise 2 kategorik değişkene (cinsiyet dahil) dayalı iki temel sınıflandırma algoritması oluşturduk. AV Datahacks’te ilk gönderiminizi oluşturmak için bunu hızlı bir şekilde kodlayabilirsiniz.
Pandaları kullanarak Python’da nasıl keşif analizi yapabileceğimizi gördük. Umarım pandalara (hayvana) olan sevginiz şimdiye kadar artardı – yardımın miktarı göz önüne alındığında, kütüphanenin veri kümelerini analiz etmede size sağlayabileceği.
Şimdi, ApplicantIncome ve LoanStatus değişkenlerini daha detaylı inceleyelim, veri karıştırma işlemini gerçekleştirelim ve çeşitli modelleme tekniklerini uygulamak için bir veri seti oluşturalım. Daha fazla okumadan önce başka bir veri seti ve problem almanızı ve bağımsız bir örnekten geçmenizi şiddetle tavsiye ederim.
4. Python’da Veri Dağıtma: Pandaları Kullanma
Takip edenler için, işte koşmaya başlamak için giymeniz gereken ayakkabılar.
Veri mugging – ihtiyacın özeti
Verileri araştırırken, veri setinde, veriler iyi bir model için hazır olmadan önce çözülmesi gereken birkaç problem bulduk. Bu alıştırma tipik olarak “Veri Mıknatıs” olarak adlandırılır. İşte zaten farkında olduğumuz sorunlar:
- Bazı değişkenlerde eksik değerler var. Kayıp değerlerin miktarına ve değişkenlerin beklenen önemine bağlı olarak bu değerleri akıllıca tahmin etmeliyiz.
- Dağılımlara bakarken, ApplicantIncome ve LoanAmount’un her iki uçta da uç değerler içerdiğini gördük. Sezgisel olarak mantıklı olsalar da, uygun şekilde tedavi edilmelidirler.
Sayısal alanlarla ilgili bu sorunlara ek olarak, herhangi bir yararlı bilgi içerip içermediğini görmek için sayısal olmayan alanlara da (Gender, Property_Area, Married, Education ve Dependents) bakmalıyız.
Pandalar konusunda yeniyseniz, devam etmeden önce bu makaleyi okumanızı tavsiye ederim. Bazı yararlı veri işleme tekniklerini detaylandırır.
Veri kümesindeki eksik değerleri kontrol edin
Tüm değişkenlerdeki eksik değerlere bakalım çünkü modellerin çoğu eksik verilerle çalışmaz ve çalışsalar bile, onları atamak çoğu zaman yardımcı olur. Öyleyse, veri kümesindeki boş / NaN sayısını kontrol edelim.
df.apply(lambda x: toplam(x.isnull()),axis=0)
Değer boşsa isnull() 1 değerini döndürdüğü için bu komut bize her sütundaki eksik değerlerin sayısını söylemelidir.
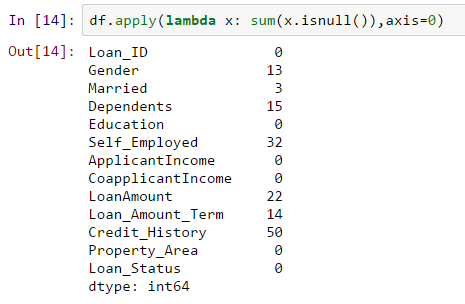
Eksik değerler sayıca çok yüksek olmasa da birçok değişkende vardır ve bunların her birinin tahmin edilip verilere eklenmesi gerekir. Bu makale aracılığıyla farklı atama teknikleri hakkında ayrıntılı bir görüş edinin.
Not: Eksik değerlerin her zaman NaN olmayabileceğini unutmayın. Örneğin, Loan_Amount_Term 0 ise, mantıklı mı yoksa bunun eksik olduğunu düşünür müsünüz? Sanırım cevabınız eksik ve haklısınız. Bu yüzden pratik olmayan değerleri kontrol etmeliyiz.
LoanAmount’ta eksik değerler nasıl doldurulur?
Kredi tutarının eksik değerlerini doldurmanın birçok yolu vardır – en basiti, aşağıdaki kodla yapılabilecek ortalama ile değiştirmedir:
df['KrediTutarı'].fillna(df['KrediTutarı'].mean(), inplace=Doğru)
Diğer uç nokta, kredi miktarını diğer değişkenler temelinde tahmin etmek için denetimli bir öğrenme modeli oluşturmak ve ardından hayatta kalmayı tahmin etmek için diğer değişkenlerle birlikte yaşı kullanmak olabilir.
Şimdi amaç veri parçalama adımlarını ortaya çıkarmak olduğundan, bu 2 uç arasında bir yerde bulunan bir yaklaşımı tercih edeceğim. Kilit bir hipotez, bir kişinin eğitimli veya serbest meslek sahibi olup olmadığının, kredi tutarının iyi bir tahminini vermek için birleşebileceğidir.
İlk önce, bir trendin olup olmadığını görmek için kutu grafiğine bakalım:
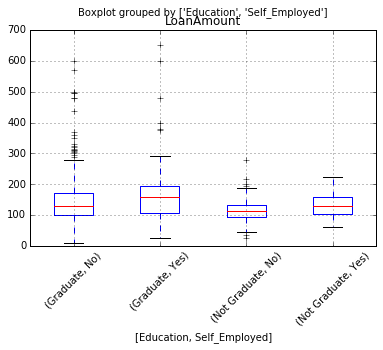
Bu nedenle, her grup için kredi tutarının medyanında bazı farklılıklar görüyoruz ve bu, değerleri hesaplamak için kullanılabilir. Ama önce, Self_Employed ve Education değişkenlerinin her birinin eksik bir değere sahip olmamasını sağlamalıyız.
Daha önce de söylediğimiz gibi Self_Employed’ın bazı eksik değerleri var. Sıklık tablosuna bakalım:
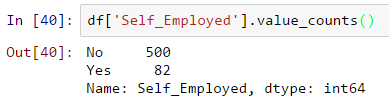
~%86 değerleri “Hayır” olduğundan, yüksek bir başarı olasılığı olduğundan eksik değerleri “Hayır” olarak kabul etmek güvenlidir. Bu, aşağıdaki kod kullanılarak yapılabilir:
df['Self_Employed'].fillna('Hayır',inplace=Doğru)
Şimdi, Serbest Çalışan ve Eğitim özelliklerinin tüm benzersiz değer grupları için bize medyan değerleri sağlayan bir Pivot tablosu oluşturacağız. Daha sonra, bu hücrelerin değerlerini döndüren ve kredi tutarının eksik değerlerini doldurmak için uygulayan bir fonksiyon tanımlıyoruz:
tablo = df.pivot_table(values='KrediAmount', index='Self_Employed' ,columns='Eğitim', aggfunc=np.medyan) # Bu pivot_table'ın değerini döndürecek işlevi tanımlayın def fage(x): tabloyu döndür.loc[x['Self_Çalışan'],x['Eğitim']] # Eksik değerleri değiştirin df['KrediAmount'].fillna(df[df['KrediAmount'].isnull()].apply(fage, axis=1), inplace=True)
Bu size kredi tutarının eksik değerlerini hesaplamak için iyi bir yol sağlamalıdır.
NOT : Bu yöntem yalnızca, Loan_Amount değişkenindeki eksik değerleri önceki yaklaşımı kullanarak, yani ortalamayı kullanarak doldurmadıysanız işe yarar.
LoanAmount ve ApplicantIncome dağılımındaki aşırı değerler nasıl ele alınır?
Önce LoanAmount’u analiz edelim. Aşırı değerler pratikte mümkün olduğundan, yani bazı kişiler özel ihtiyaçlardan dolayı yüksek değerli kredilere başvurabilirler. Bu nedenle, bunları aykırı değerler olarak ele almak yerine, etkilerini geçersiz kılmak için bir günlük dönüşümü deneyelim:
df['KrediAmount_log'] = np.log(df['KrediAmount']) df['KrediAmount_log'].hist(bins=20)
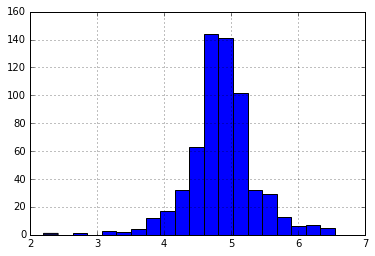
Histograma tekrar baktığımızda:
Artık dağılım normale çok daha yakın görünüyor ve aşırı değerlerin etkisi önemli ölçüde azaldı.
ApplicantIncome’a geliyor. Bir sezgi, bazı başvuru sahiplerinin daha düşük gelire sahip olduğu, ancak Eş-başvuranların güçlü destek aldığı olabilir. Bu nedenle, her iki geliri toplam gelir olarak birleştirmek ve aynısının log dönüşümünü almak iyi bir fikir olabilir.
df['TotalIncome'] = df['ApplicantIncome'] + df['CoapplicantIncome'] df['TotalIncome_log'] = np.log(df['TotalIncome']) df['KrediAmount_log'].hist(bins=20)
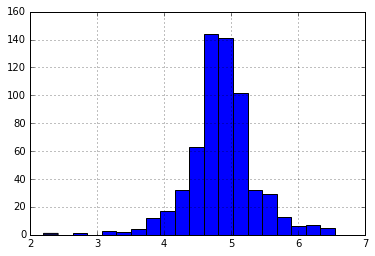
Şimdi dağılımın eskisinden çok daha iyi olduğunu görüyoruz. Gender, Married, Dependents, Loan_Amount_Term, Credit_History için eksik değerlerin hesaplanmasını size bırakacağım. Ayrıca, verilerden elde edilebilecek olası ek bilgiler hakkında düşünmenizi tavsiye ederim. Örneğin, LoanAmount/TotalIncome için bir sütun oluşturmak, başvuranın kredisini geri ödemeye ne kadar uygun olduğuna dair bir fikir verdiği için mantıklı olabilir.
Ardından, tahmine dayalı modeller oluşturmaya bakacağız.
5. Python’da Tahmine Dayalı Bir Model Oluşturma
Verileri modelleme için kullanışlı hale getirdikten sonra şimdi veri setimiz üzerinde tahmine dayalı bir model oluşturmak için python koduna bakalım. Skicit-Learn (sklearn), Python’da bu amaç için en yaygın kullanılan kütüphanedir ve biz de izini süreceğiz. Bu makale aracılığıyla sklearn hakkında bilgi tazelemenizi tavsiye ederim.
Sklearn tüm girdilerin sayısal olmasını gerektirdiğinden, kategorileri kodlayarak tüm kategorik değişkenlerimizi sayısala çevirmeliyiz. Ondan önce veri setindeki tüm eksik değerleri dolduracağız. Bu, aşağıdaki kod kullanılarak yapılabilir:
df['Gender'].fillna(df['Gender'].mode()[0], inplace=Doğru) df['Evli'].fillna(df['Evli'].mode()[0], inplace=Doğru) df['Bağımlılıklar'].fillna(df['Bağımlılıklar'].mode()[0], inplace=Doğru) df['Kredi_Amount_Term'].fillna(df['Kredi_Amount_Term'].mode()[0], inplace=Doğru) df['Credit_History'].fillna(df['Credit_History'].mode()[0], inplace=Doğru)
sklearn.preprocessing'den LabelEncoder'ı içe aktarın
var_mod = ['Cinsiyet','Evli','Bağımlı Kişiler','Eğitim','Kendi_Çalışan','Mülk_Alan','Kredi_Durumu']
le = LabelEncoder()
var_mod'daki i için:
df[i] = le.fit_transform(df[i])
df.dtypes
Ardından, gerekli modülleri içe aktaracağız. Ardından, girdi olarak bir modeli alan ve Doğruluk ve Çapraz Doğrulama puanlarını belirleyen genel bir sınıflandırma işlevi tanımlayacağız. Bu bir giriş yazısı olduğu için kodlamanın detaylarına girmeyeceğim. R ve Python kodlu algoritmaların detaylarını almak için lütfen bu makaleye bakınız. Ayrıca, güç performansının çok önemli bir ölçüsü olduğundan, bu makale aracılığıyla çapraz doğrulama hakkında bilgi tazelemek iyi olacaktır .
#Scikit öğrenme modülünden modelleri içe aktar:
sklearn.linear_model'den LogisticRegression'ı içe aktarın
sklearn.cross_validation'dan içe aktarma KFold #K-kat çapraz doğrulama için
sklearn.ensemble'dan RandomForestClassifier'ı içe aktarın
sklearn.tree'den DecisionTreeClassifier'ı içe aktarın, export_graphviz
sklearn içe aktarma metriklerinden
#Sınıflandırma modeli yapmak ve performansa erişmek için genel işlev:
def sınıflandırma_modeli(model, veri, tahmin ediciler, sonuç):
#Modele sığdır:
model.fit(veri[öngörücüler],veri[sonuç])
#Eğitim setinde tahminlerde bulunun:
tahminler = model.predict(veri[predictors])
#Baskı doğruluğu
doğruluk = metrics.accuracy_score(tahminler,veri[sonuç])
print ("Doğruluk : %s" % "{0:.3%}".format(doğruluk))
#5 kat ile k kat çapraz doğrulama gerçekleştirin
kf = KFold(veri.şekil[0], n_folds=5)
hata = []
tren için, kf'de test edin:
# Eğitim verilerini filtrele
train_predictors = (veri[predictors].iloc[tren,:])
# Algoritmayı eğitmek için kullandığımız hedef.
train_target = veri[sonuç].iloc[tren]
# Öngörücüleri ve hedefi kullanarak algoritmayı eğitmek.
model.fit(train_predictors, train_target)
#Her çapraz doğrulama çalıştırmasında hatayı kaydet
error.append(model.score(veri[öngörüler].iloc[test,:], veri[sonuç].iloc[test]))
print ("Çapraz Doğrulama Puanı : %s" % "{0:.3%}".format(np.mean(hata)))
#Fonksiyonun dışında başvurulabilmesi için modeli tekrar sığdır:
model.fit(veri[öngörücüler],veri[sonuç])
Lojistik regresyon
İlk Lojistik Regresyon modelimizi yapalım. Bir yol, tüm değişkenleri modele almak olabilir, ancak bu, fazla uyumla sonuçlanabilir (henüz bu terminolojiden haberiniz yoksa endişelenmeyin). Basit bir deyişle, tüm değişkenleri almak, modelin verilere özgü karmaşık ilişkileri anlamasına neden olabilir ve iyi genelleme yapmaz. Lojistik Regresyon hakkında daha fazlasını okuyun .
Topun yuvarlanmasını sağlamak için kolayca bazı sezgisel hipotezler yapabiliriz. Aşağıdakiler için kredi alma şansı daha yüksek olacaktır:
- Kredi geçmişi olan adaylar (bunu keşifte gözlemlediğimizi hatırlıyor musunuz?)
- Başvuru sahibi ve eş-başvuran geliri daha yüksek olan başvuru sahipleri
- Yüksek öğrenim düzeyine sahip adaylar
- Yüksek büyüme perspektifine sahip kentsel alanlardaki mülkler
O halde ‘Credit_History’ ile ilk modelimizi yapalım.
sonuç_var = 'Kredi_Durumu' model = LojistikRegresyon() predictor_var = ['Credit_History'] sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %80,945 Çapraz Doğrulama Puanı : %80,946
#Farklı değişken kombinasyonlarını deneyebiliriz: predictor_var = ['Credit_History','Eğitim','Evli','Self_Employed','Property_Area'] sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %80,945 Çapraz Doğrulama Puanı : %80,946
Genellikle, değişkenlerin eklenmesiyle doğruluğun artmasını bekleriz. Ama bu daha zorlu bir durum. Doğruluk ve çapraz doğrulama puanı, daha az önemli değişkenlerden etkilenmez. Credit_History moda hakim. Şimdi iki seçeneğimiz var:
- Özellik Mühendisliği: yeni bilgiler elde edin ve bunları tahmin etmeye çalışın. Bunu sizin yaratıcılığınıza bırakıyorum.
- Daha iyi modelleme teknikleri. Bunu bir sonraki keşfedelim.
Karar ağacı
Karar ağacı, tahmine dayalı bir model oluşturmanın başka bir yöntemidir. Lojistik regresyon modelinden daha yüksek doğruluk sağladığı bilinmektedir. Karar Ağaçları hakkında daha fazla bilgi edinin .
model = Karar AğacıSınıflandırıcı() predictor_var = ['Credit_History','Gender','Evli','Eğitim'] sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %81.930 Çapraz Doğrulama Puanı : %76,656
Burada, kategorik değişkenlere dayalı modelin bir etkisi olamaz çünkü Kredi Geçmişi onlara hakimdir. Birkaç sayısal değişken deneyelim:
#Farklı değişken kombinasyonlarını deneyebiliriz: predictor_var = ['Credit_History','Loan_Amount_Term','LoanAmount_log'] sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %92.345 Çapraz Doğrulama Puanı : %71.009
Burada, değişkenlerin eklenmesiyle doğruluğun artmasına rağmen çapraz doğrulama hatasının düştüğünü gözlemledik. Bu, modelin verilere gereğinden fazla uymasının sonucudur. Daha da karmaşık bir algoritma deneyelim ve yardımcı olup olmadığına bakalım:
Rastgele Orman
Rastgele orman, sınıflandırma problemini çözmek için başka bir algoritmadır. Rastgele Orman hakkında daha fazla bilgi edinin .
Random Forest’ın bir avantajı, tüm özelliklerle çalışmasını sağlayabilmemiz ve özellikleri seçmek için kullanılabilecek bir özellik önem matrisi döndürmesidir.
model = RandomForestClassifier(n_estimators=100)
predictor_var = ['Cinsiyet', 'Evli', 'Bakımlılar', 'Eğitim',
'Self_Çalışan', 'Kredi_Amount_Term', 'Kredi_Geçmişi', 'Mülk_Alan',
'KrediAmount_log','TotalIncome_log']
sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %100.000 Çapraz Doğrulama Puanı : %78.179
Burada eğitim seti için doğruluğun %100 olduğunu görüyoruz. Bu, aşırı takmanın nihai durumudur ve iki şekilde çözülebilir:
- Tahmin edicilerin sayısını azaltmak
- Model parametrelerinin ayarlanması
Bu ikisini deneyelim. İlk önce, en önemli özellikleri alacağımız özellik önem matrisini görüyoruz.
#Önemli özelliklere sahip bir dizi oluştur: featimp = pd.Series(model.feature_importances_, index=predictor_var).sort_values(artan=Yanlış) baskı (featimp)
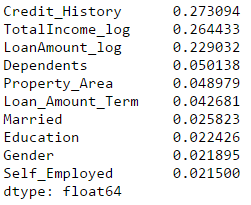
Bir model oluşturmak için ilk 5 değişkeni kullanalım. Ayrıca rastgele orman modelinin parametrelerini biraz değiştireceğiz:
model = RandomForestClassifier(n_estimators=25, min_samples_split=25, max_depth=7, max_features=1) prector_var = ['TotalIncome_log','LoanAmount_log','Credit_History','Bağımlılıklar','Property_Area'] sınıflandırma_modeli(model, df,predictor_var,outcome_var)
Doğruluk : %82.899 Çapraz Doğrulama Puanı : %81,461
Doğruluğun azalmasına rağmen, çapraz doğrulama puanının arttığına ve modelin iyi genelleme yaptığını gösterdiğine dikkat edin. Rastgele orman modellerinin tam olarak tekrarlanabilir olmadığını unutmayın. Farklı çalıştırmalar, rastgeleleştirme nedeniyle küçük farklılıklara neden olacaktır. Ancak çıktı, basketbol sahasında kalmalıdır.
Rastgele ormanda bazı temel parametre ayarlamalarından sonra bile, orijinal lojistik regresyon modelinden yalnızca biraz daha iyi bir çapraz doğrulama doğruluğuna ulaştığımızı fark etmişsinizdir. Bu alıştırma bize çok ilginç ve benzersiz bazı bilgiler veriyor:
- Daha sofistike bir model kullanmak daha iyi sonuçları garanti etmez.
- Temel kavramları anlamadan karmaşık modelleme tekniklerini kara kutu olarak kullanmaktan kaçının. Bunu yapmak, fazla takma eğilimini artıracak ve böylece modellerinizi daha az yorumlanabilir hale getirecektir.
- Özellik Mühendisliği başarının anahtarıdır. Herkes bir Xgboost modelini kullanabilir, ancak gerçek sanat ve yaratıcılık, özelliklerinizi modele daha iyi uyacak şekilde geliştirmekte yatar.
Bu gönderide kullanılan veri kümesine ve sorun bildirimine şu bağlantıdan erişebilirsiniz: Loan Prediction Challenge
Projeler
Şimdi, dalmaya başlama ve aslında diğer bazı gerçek veri kümeleriyle oynama zamanı. Öyleyse meydan okumaya hazır mısın? Aşağıdaki Alıştırma Problemleriyle veri bilimi yolculuğunuzu hızlandırın:
| Alıştırma Problemi: Gıda Talebi Tahmini Zorluğu | Bir yemek dağıtım şirketi için yemek talebini tahmin edin | |
| Alıştırma Problemi: İK Analitiği Mücadelesi | Terfi alma olasılığı en yüksek çalışanları belirleyin | |
| Alıştırma Problemi: Olumlu Oy Sayısını Tahmin Et | Çevrimiçi bir soru-cevap platformunda sorulan bir sorgudaki olumlu oyların sayısını tahmin edin |
Bitiş Notları
Umarım bu eğitim, Python’da veri bilimine başlarken verimliliğinizi en üst düzeye çıkarmanıza yardımcı olur. Eminim bu size yalnızca temel veri analizi yöntemleri hakkında bir fikir vermekle kalmadı, aynı zamanda bugün mevcut olan daha karmaşık tekniklerin bazılarını nasıl uygulayacağınızı da gösterdi.
Ayrıca ücretsiz Python kursumuza göz atmalı ve ardından bunu Data Science için nasıl uygulayacağınızı öğrenmek için atlamalısınız .
Python gerçekten harika bir araçtır ve veri bilimcileri arasında giderek daha popüler bir dil haline gelmektedir. Bunun nedeni, öğrenmesinin kolay olmasıdır, Spark ve Hadoop gibi diğer veritabanları ve araçlarla iyi bir şekilde bütünleşir. Büyük ölçüde, büyük bir hesaplama yoğunluğuna ve güçlü veri analizi kitaplıklarına sahiptir.
Bu nedenle, herhangi bir veri bilimi projesinin tüm yaşam döngüsünü gerçekleştirmek için Python’u öğrenin. Okumayı, analiz etmeyi, görselleştirmeyi ve son olarak tahminlerde bulunmayı içerir.
Tüm yazılarımızı buradan okuyabilirsiniz.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}